一.socket
1.简介
socket
套接字:对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。
例如:两个人通过电话进行通信,两个人都需要持有1个电话,socket 就类似于这个电话。
FD:file descriptor
文件描述符,非负整数。“一切皆文件”,linux 中的一切资源都可以通过文件的方式访问和管理。而 FD 就类似文件的索引(符号、指针),指向某个资源,内核(kernel)利用 FD 来访问和管理资源。
2.socket通信
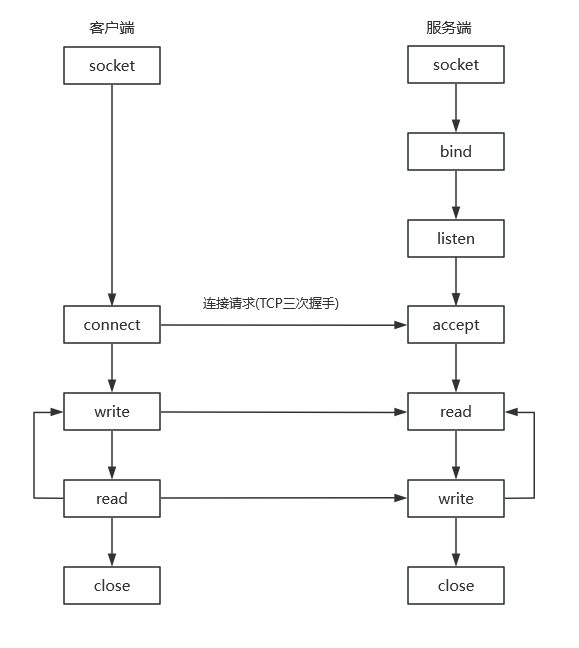
socket:创建一个套接字
bind:将 socket 绑定到指定地址
listen:使套接字处于监听状态,等待客户端连接到来
accept:接受客户端连接
connect:客户端发起连接
read:从 fd 对应的 socket 中读取数据
write:将数据写入 fd 对应的 socket 中
close:关闭 socket 文件描述符
(1)服务器端通过 socket、bind、listen 对 socket 进行初始化,最后阻塞在 accept 等待客户端请求到来。
(2)客户端通过 socket 进行初始化,然后使用 connect 向服务端发起连接请求。此时客户端会和服务端进行 TCP 三次握手,三次握手完成后,客户端和服务端建立连接完毕,开始进入数据传输过程。
(3)客户端发起 write 系统调用写入数据,数据从用户空间拷贝到内核空间 socket 缓冲区,最后内核将数据通过网络发送到服务器。
(4)数据经过网络传输到达服务器网卡,接着内核将数据拷贝到对应的 socket 接收队列,最后将数据从内核空间拷贝到用户空间。
(5)客户端和服务器完成交互后,调用 close 函数来断开连接。
二.IO多路复用
1.简介
IO 多路复用是一种同步 IO 模型,实现一个线程可以监视多个文件句柄。一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出 cpu。IO 是指网络 IO,多路指多个TCP连接(即 socket 或者 channel),复用指复用一个或几个线程。
意思说一个或一组线程处理多个 TCP 连接。最大优势是减少系统开销小,不必创建过多的进程/线程,也不必维护这些进程/线程。IO 多路复用的三种实现方式:select、poll、epoll。
2.优点和缺点
2.1优点
高效性:通过单个线程同时管理多个IO通道,减少了线程的创建和销毁开销,提高了系统的并发性能。
资源节约:相比每个通道创建一个独立的线程,IO多路复用可以使用更少的线程来处理大量的IO通道,节约了系统资源。
简化编程模型:使用IO多路复用可以将异步IO操作转换为同步的事件驱动模型,简化了编程逻辑和代码复杂度。
可扩展性:由于使用了事件驱动模型,IO多路复用可以轻松地扩展到更多的IO通道,而不需要修改大量的代码。
2.2缺点
学习曲线较陡:相比于传统的多线程或多进程模型,IO多路复用的概念和使用方式可能需要一些学习和理解。
对编程模型的要求较高:使用IO多路复用需要合理地设计和处理事件驱动的逻辑,否则可能会导致代码复杂、难以维护。
不适用于CPU密集型任务:IO多路复用适用于IO密集型任务,而对于CPU密集型任务,使用多线程或多进程模型可能更为合适
3.应用场景
网络编程:在网络编程中,服务器通常需要同时处理多个客户端的连接请求和数据传输。使用IO多路复用可以轻松管理多个网络套接字,监听并处理可读或可写的事件。这种方式可以实现高并发的服务器,提高系统的性能和扩展性。
高性能服务器:对于需要处理大量并发连接的服务器,如聊天服务器、实时通信服务器、游戏服务器等,使用IO多路复用可以有效地管理和处理多个客户端连接,提高服务器的吞吐量和响应速度。
文件操作:在文件操作中,当需要同时读取或写入多个文件时,可以使用IO多路复用来监听文件描述符的可读或可写事件,从而避免使用多线程或多进程的方式,提高文件操作的效率。
定时器和事件调度:IO多路复用可以用于实现定时器和事件调度功能。通过将定时器和事件的触发时间注册到IO多路复用机制中,可以在特定的时间点触发相应的事件,执行相应的操作。
4.IO多路复用机制
4.1 同步阻塞(BIO)
最传统的一种IO模型,即在读写数据过程中会发生阻塞现象。
4.2 同步非阻塞(NIO)
当用户线程发起一个 IO 操作后,并不需要等待,而是马上就得到一个结果。如果结果是一个 error 时,它就知道数据还没有准备好,于是它可以再次发送 IO 操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。
4.3 IO多路复用
在多路复用IO模型中,会有一个内核线程不断地去轮询多个 socket 的状态,只有当真正读写事件发送时,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有真正有读写事件进行时,才会使用IO资源,所以它大大减少来资源占用。
5.IO多路复用实现
| 类型 | select | poll | epoll |
|---|
| 操作方式 | 遍历 | 遍历 | 回调 |
| 数据结构 | bitmap | 数组 | 红黑树 |
| 最大连接数 | 1024 | 无上限 | 无上限 |
| fd拷贝 | 每次调用select拷贝,都需要把fd集合从用户态拷贝到内核态 | 每次调用poll拷贝,都需要把fd集合从用户态拷贝到内核态 | fd首次调用epoll_ctl拷贝,每次调用epoll_wait不拷贝 |
| 工作模式 | LT | LT | 支持ET高效模式 |
| 工作效率 | 每次调用都进行线性遍历,时间复杂度O(n) | 每次调用都进行线性遍历,时间复杂度O(n) | 事件通知方式,每当fd就绪,系统注册的回调函数就会被调用,将就绪的fd放到readyList里面,时间复杂度O(1) |
5.1select
5.1.1原理
客户端操作服务器时就会产生这三种文件描述符(简称fd):writefds(写)、readfds(读)、和 exceptfds(异常)。select 会阻塞住监视 3 类文件描述符,等有数据、可读、可写、出异常或超时就会返回;返回后通过遍历 fdset 整个数组来找到就绪的描述符 fd,然后进行对应的 IO 操作。
5.1.2优点
几乎在所有的平台上支持,跨平台支持性好
5.1.3缺点
由于是采用轮询方式全盘扫描,会随着文件描述符 FD 数量增多而性能下降。
每次调用 select(),都需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)。
单个进程打开的 FD 是有限制(通过FD_SETSIZE设置)的,默认是 1024 个,可修改宏定义,但是效率仍然慢。
5.2poll
5.2.1原理
基本原理与 select 一致,也是轮询+遍历。唯一的区别就是 poll 没有最大文件描述符限制(使用链表的方式存储 fd)。
5.2.2缺点
由于是采用轮询方式全盘扫描,会随着文件描述符 FD 数量增多而性能下降。
每次调用 select(),都需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)。
5.3epoll
5.3.1原理
没有 fd 个数限制,用户态拷贝到内核态只需要一次,使用时间通知机制来触发。通过 epoll_ctl 注册 fd,一旦 fd 就绪就会通过 callback 回调机制来激活对应 fd,进行相关的 io 操作。epoll 之所以高性能是得益于它的三个函数:
epoll_create() 系统启动时,在 Linux 内核里面申请一个B+树结构文件系统,返回 epoll 对象,也是一个 fd。
epoll_ctl() 每新建一个连接,都通过该函数操作 epoll 对象,在这个对象里面修改添加删除对应的链接 fd,绑定一个 callback 函数
epoll_wait() 轮训所有的 callback 集合,并完成对应的 IO 操作
5.3.2优点
没 fd 这个限制,所支持的 FD 上限是操作系统的最大文件句柄数,1G 内存大概支持 10 万个句柄。效率提高,使用回调通知而不是轮询的方式,不会随着 FD 数目的增加效率下降。内核和用户空间 mmap 同一块内存实现(mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间)
5.3.3缺点
epoll 只能工作在linux下。




评论区