一.promtheus简介
1.简介
Prometheus是一个开源的系统监控和报警系统,现在已经加入到CNCF基金会,成为继k8s之后第二个在CNCF托管的项目,在kubernetes容器管理系统中,通常会搭配prometheus进行监控,同时也支持多种exporter采集数据,还支持pushgateway进行数据上报,Prometheus性能足够支撑上万台规模的集群。
2.promtheus特点
(1)多维度数据模型
每一个时间序列数据都由metric度量指标名称和它的标签labels键值对集合唯一确定:这个metric度量指标名称指定监控目标系统的测量特征(如:http_requests_total- 接收http请求的总计数)。labels开启了Prometheus的多维数据模型:对于相同的度量名称,通过不同标签列表的结合, 会形成特定的度量维度实例。(例如:所有包含度量名称为/api/tracks的http请求,打上method=POST的标签,则形成了具体的http请求)。这个查询语言在这些度量和标签列表的基础上进行过滤和聚合。改变任何度量上的任何标签值,则会形成新的时间序列图。
(2)灵活的查询语言(PromQL):可以对采集的metrics指标进行加法,乘法,连接等操作;
(3)可以直接在本地部署,不依赖其他分布式存储;
(4)通过基于HTTP的pull方式采集时序数据;
(5)可以通过中间网关pushgateway的方式把时间序列数据推送到prometheus server端;
(6)可通过服务发现或者静态配置来发现目标服务对象(targets)。
(7)有多种可视化图像界面,如Grafana等。
(8)高效的存储,每个采样数据占3.5 bytes左右,300万的时间序列,30s间隔,保留60天,消耗磁盘大概200G。
(9)做高可用,可以对数据做异地备份,联邦集群,部署多套prometheus,pushgateway上报数据
3.promtheus组件
3.1promtheus工作组件
(1)Prometheus Server: 用于收集和存储时间序列数据。
(2)Exporters: prometheus支持多种exporter,通过exporter可以采集metrics数据,然后发送到prometheus server端
(3)Alertmanager: 从 Prometheus server 端接收到告警后,会进行去重,分组,并路由到相应的接收方,发出报警,常见的接收方式有:邮件,企业微信,钉钉
(4)Grafana:监控仪表盘,可视化监控数据
(5)pushgateway: 各个目标主机可上报数据到pushgateway,然后prometheus server统一从pushgateway拉取数据。
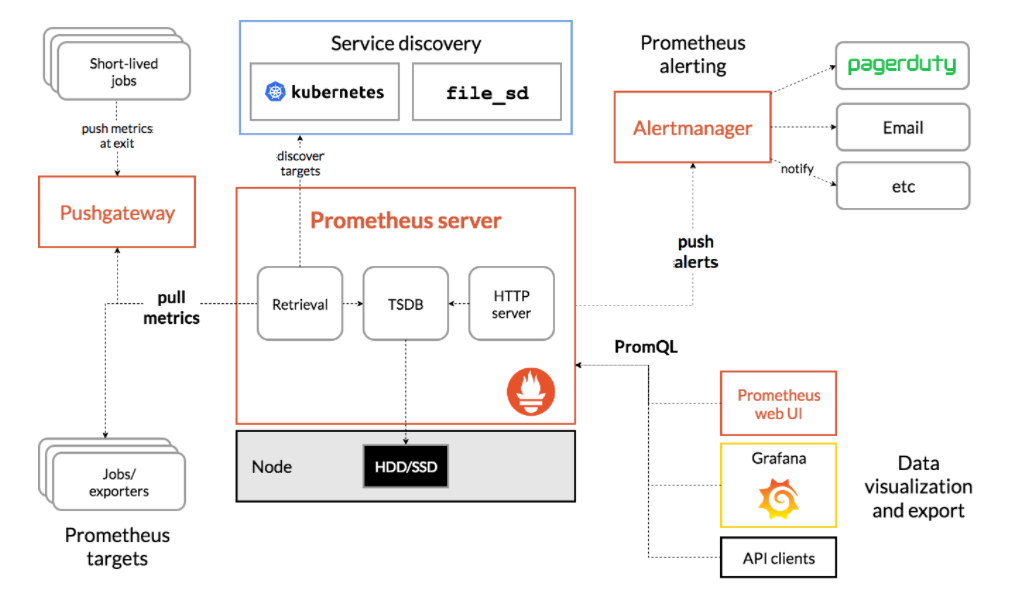
3.2prometheus组件
(1)Retrieval负责在活跃的target主机上抓取监控指标数据
(2)Storage存储主要是把采集到的数据存储到磁盘中
(3)PromQL是Prometheus提供的查询语言模块。
4.prometheus工作流程
(1)Prometheus server可定期从活跃的(up)目标主机上(target)拉取监控指标数据,目标主机的监控数据可通过配置静态job或者服务发现的方式被prometheus server采集到,这种方式默认的pull方式拉取指标;也可通过pushgateway把采集的数据上报到prometheus server中
(2)Prometheus server把采集到的监控指标数据保存到本地磁盘或者数据库;
(3)Prometheus采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到alertmanager
(4)Alertmanager通过配置报警接收方,发送报警到邮件,微信或者钉钉等
(5)Prometheus 自带的web ui界面提供PromQL查询语言,可查询监控数据
(6)Grafana可接入prometheus数据源,把监控数据以图形化形式展示出
二.promtheus语句
1.数据类型
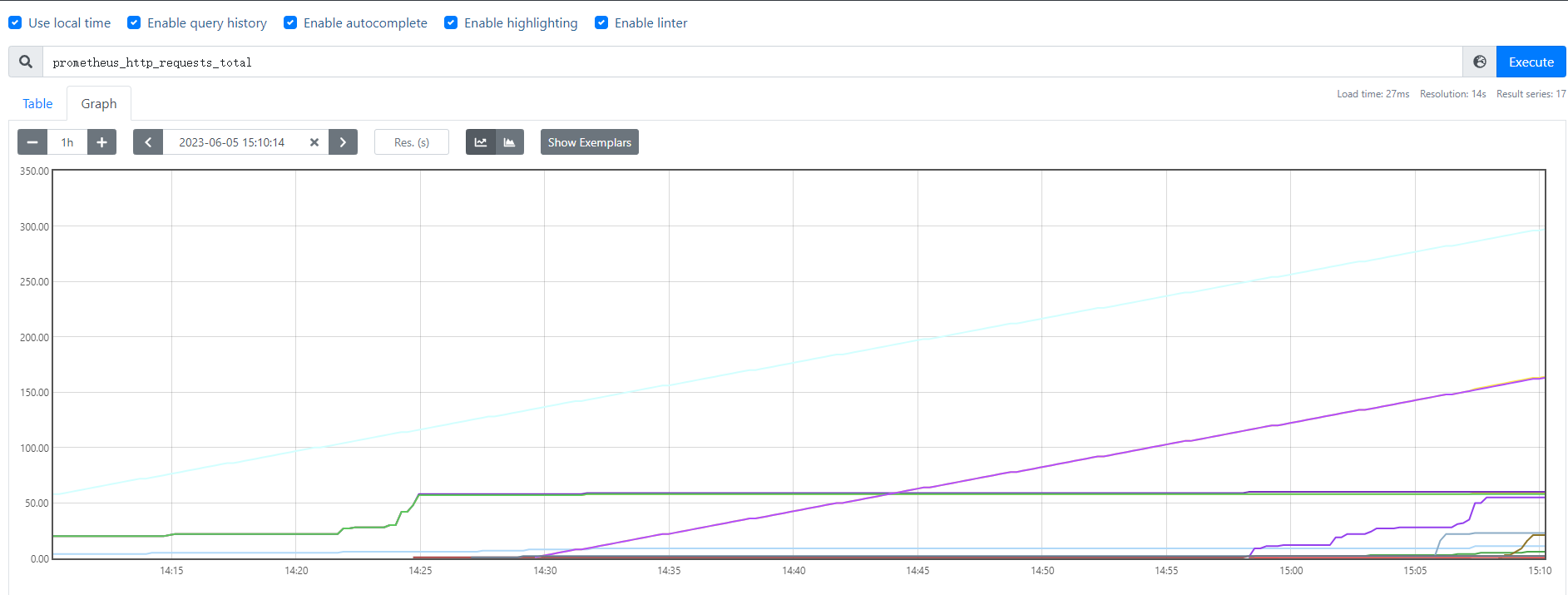
1.1计数器(Counter)
从数据量为0开始累积计算,在理想状态下只能永远增长,不会降低,例如对用户访问量的采样数据;
Counter数据类型的特点:
Counter 用于累计值,例如 记录 请求次数、任务完成数、错误发生次数。
一直增加,不会减少。
重启进程后,会被重置。
案例:
prometheus_http_requests_total #http请求量
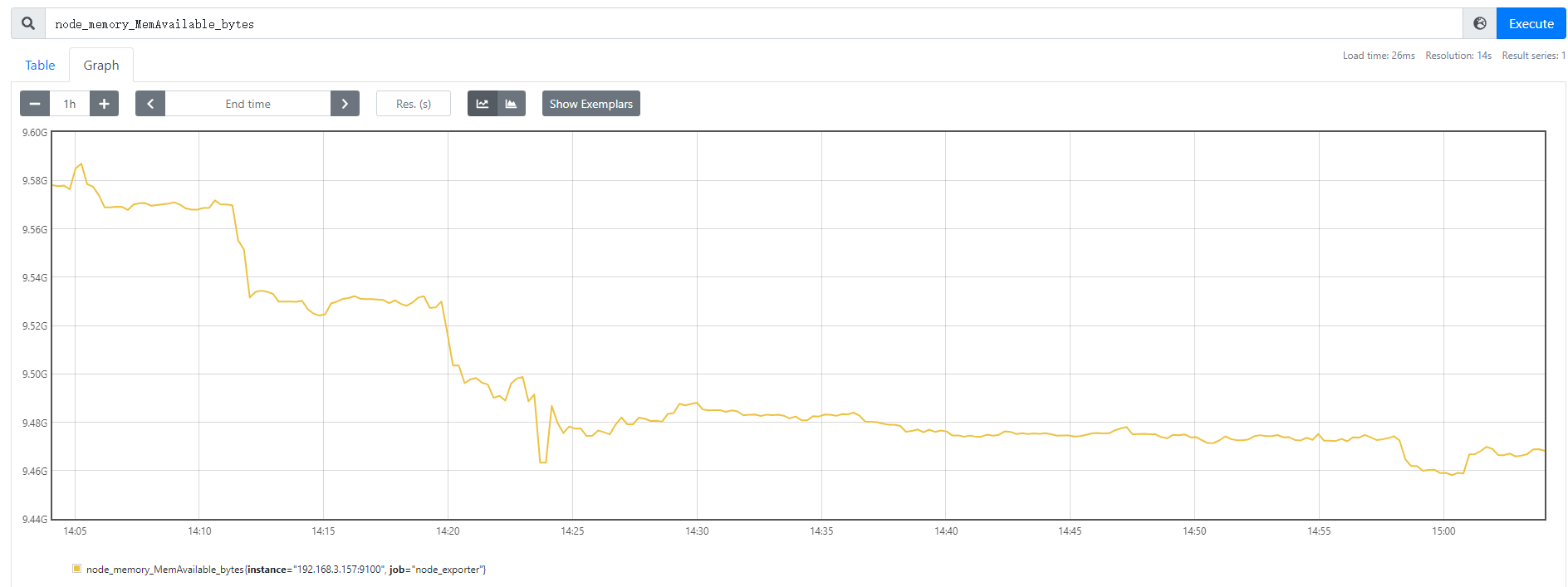
1.2仪表(Gauge)
最简单的度量指标,只有一个简单的返回值(瞬时状态),例如监控磁盘或者内存的使用量,那么就应该使用gauges格式来度量;
Gauge数据类型的特点:
Gauge 常规数值,例如 温度变化、内存使用变化。
可变大,可变小。
重启进程后,会被重置
案例:
node_memory_Active_bytes /1024/1024/1024 #node剩余内存
1.3直方图(Histogram)
histogram是柱状图
Histogram:累积直方图,会在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等)
1.4汇总(Summary)
Summary直方图
通过计算分位数(quantile)显示指标结果,可用于统计一段时间内数据采样结果
2.匹配器
=: 精确的匹配指定的标签值
!=: 不匹配指定的标签值,取反
=~: 正则表达式匹配指定的标签值
!~: 不匹配正则表格式指定的标签值
node_memory_MemTotal_bytes{instance="192.168.3.157:9100"} #精准匹配
node_memory_MemTotal_bytes{instance!="192.168.3.157:9100"} #匹配取反
node_memory_MemTotal_bytes{instance=~"192.168.3.*:9100"} #正则匹配
node_memory_MemTotal_bytes{instance!~"192.168.3.*:9100"} #正则取反
3.算数运算
+:加法;
-:减法;
*:乘法;
/:除法;
^:幂运算;
node_memory_MemTotal_bytes/1024/1024/1024 #将内存单位从字节转换为G
(node_memory_MemTotal_bytes-node_memory_MemFree_bytes)/1024/1024/1024 #所有内存-剩余内存=已使用内存
4.时间格式
ms(毫秒)、s(秒)、m(分钟)、h(小时)、d(天)、w(周)、y(年)
d 表示一天总是24小时
w 表示一周总是7天
y 表示一年总是365天
node_memory_MemFree_bytes[5m] #查看5分钟内的数据
node_memory_MemFree_bytes[1d] #查看1天内的数据
5.聚合运算
5.1max,min,avg
max() 最大值
min() 最小值
avg() 平均值
max(prometheus_http_requests_total) #http请求量最大值
min(prometheus_http_requests_total) #http请求量最小值
avg(prometheus_http_requests_total) #http请求量平均值
5.2sum,count
sum() 求数据值相加的总和
sum(prometheus_http_requests_total) #http所有请求的和
count() 统计返回值的条数
count(probe_http_version)
一条返回的数据,统计所有的http_version条数
5.3abs,absent
abs 返回指标数据的值
abs(node_memory_MemTotal_bytes/1024/1024/1024)
absent #监控指标有数据就返回空,没有数据就返回1,可用于对监控项设置告警通知
absent(node_memory_MemTotal_bytes/1024/1024/1024)
5.4stddev,stdvar
stddev 标准差,统计系统波动的大小,不稳定
stddev(node_memory_MemTotal_bytes/1024/1024/1024)
stdvar 求方差
stdvar(node_memory_MemTotal_bytes/1024/1024/1024)
5.5topk,bottomk
topk //样本值最大的n个数据
#取剩余内存从大到小的前5个
topk(5,prometheus_http_requests_total)
bottomk //取样本值排名最小的n个数据
#取剩余内存从小到大的前5个
bottomk(5,prometheus_http_requests_total)
5.6rate
rate 函数专门搭配counter数据类型使用函数,功能是取conunter数据类型这个时间段中平均每秒的增量平均数据
rate(node_network_receive_bytes_total[5m])
5.7by,without
by 保留by指定的标签的值,移除其他值
max(prometheus_http_requests_total) by (instance)
without 移除列举的标签的值,保留其他的标签
max(prometheus_http_requests_total/1024/1024/1024) without (instance)




评论区